AI-Powered Developer Tools Roundup - 2024-06-29
Agent-Driven Automatic Software Improvement
- A doctoral research proposal focusing on the deployment of LLM-powered agents for software maintenance tasks.
- Addresses last-mile problems, errors at the final stage of producing functionally and contextually relevant code.
- Uses an iterative feedback system where agents correct and learn from each other's errors, fine-tuning the LLMs for better alignment.
- Aims to develop new tools and frameworks to enhance the efficiency and reliability of software development.
Agent-Driven Automatic Software Improvement
Unit Test Generation Using LLMs
- Five open-source LLMs were evaluated for unit test generation based on 17 Java projects.
- The study highlights the influence of different prompting strategies, compared the performance of these LLMs to GPT-4 and Evosuite, and identified limitations in LLM-based unit test generation.
An Empirical Study of Unit Test Generation with Large Language Models
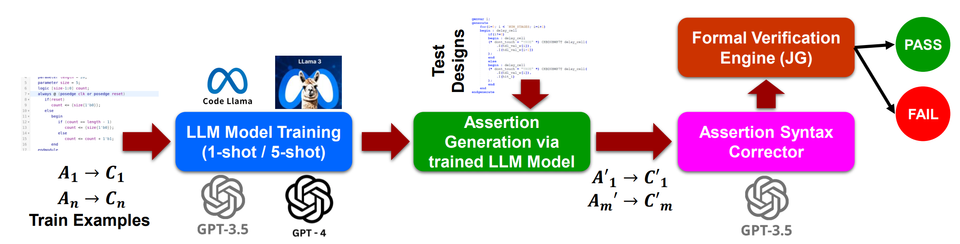
AssertionBench: A Benchmark for Evaluating LLMs in Assertion Generation
- A benchmark to evaluate the effectiveness of LLMs in generating assertions for hardware design verification.
- Includes 100 curated Verilog hardware designs from OpenCores with formally verified assertions from GoldMine and HARM.
- Compares state-of-the-art LLMs, highlighting their performance in producing functionally correct assertions and the impact of in-context exemplars.
- Identifies significant room for improvement in LLM-based assertion generators.
AssertionBench: A Benchmark to Evaluate Large-Language Models for Assertion Generation
Generating UI Code from Screenshots Using a Divide-and-Conquer Approach
- A study on GPT-4o identifies three issues in generating UI code: element omission, element distortion, and element misarrangement.
- Smaller visual segments help multimodal LLMs reduce these failures.
- A tool, DCGen, divides screenshots into segments, generates descriptions for each, and reassembles them into complete UI code.
- Tests with real-world websites and various MLLMs show up to a 14% improvement in visual similarity over competing methods.
Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
- A benchmark assessing LLMs' ability to handle practical programming tasks by invoking multiple function calls from 139 libraries across 7 domains for 1,140 fine-grained tasks.
- Each task includes 5.6 test cases on average, with 99% branch coverage.
- A variant, Benchi, transforms original docstrings into concise instructions.
- Evaluation of 60 LLMs reveals a maximum score of 60%, compared to human performance of 97%, highlighting room for improvement.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
CasModaTest: A Framework for Unit Test Generation
- A cascaded, model-agnostic framework for generating unit tests in two stages: test prefix generation and test oracle generation.
- Manually built demo pools provide high-quality test prefixes and test oracles, which are automatically assembled and compiled or executed to ensure effectiveness.
- Outperforms four state-of-the-art approaches on the Defects4J dataset with significant improvements in accuracy (60.62%-352.55%) and focal method coverage (2.83%-87.27%).
- Shows substantial improvements over state-of-the-art approaches using different open-source LLMs, with gains in accuracy (39.82%-293.96%) and focal method coverage (9.25%-98.95%).
CasModaTest: A Cascaded and Model-agnostic Self-directed Framework for Unit Test Generation
Iterative Binary Malware Summarization Framework
- A framework for generating human-readable descriptions of malware behaviors from executable files to aid malware cracking and detection.
- Addresses issues such as poor usability, inaccurate explanations, and incomplete summaries caused by obscure pseudocode structures and lack of malware training summaries.
- Constructs initial malware summaries using an LLM and refines them manually, tuning a novel LLM-based code model on these datasets.
- Iteratively feeds pseudocode functions into the model to improve understanding of pseudocode structure and function interactions.
- Introduces a novel evaluation benchmark to measure the quality of summaries, showing effectiveness across three datasets.
Self-Constructed Context Decompilation with Fine-grained Alignment Enhancement
- A method that recompiles LLM decompilation results to construct pairs for in-context learning, improving performance without fine-tuning.
- Fine-grained Alignment Enhancement aligns assembly code with source code at the statement level using debugging information during fine-tuning for further improvement.
- Integrating these methods resulted in a 7.35% improvement in Re-Executability on the Decompile-Eval benchmark, achieving a new state-of-the-art performance of 55.03%.
Self-Constructed Context Decompilation with Fined-grained Alignment Enhancement
LLM4PR: Program Refinement Tool
- A tool that combines formal program refinement techniques with LLM-based methods.
- Transforms specifications into preconditions and postconditions, builds prompts based on refinement calculus, interacts with LLM to generate code, and verifies code correctness.
- Implemented using GPT4, Coq, and Coqhammer, and evaluated on HumanEval and EvalPlus datasets.